
开篇思考
- MQ 为什么在系统中使用?一定要在分布式系统中使用吗?
- MQ 有哪些中间件?他们有哪些特点?
- MQ 给系统带来好处的同时有没有带来什么问题?如何解决?
在阿里的面试中,面试官问到关于 MQ 的几个问题:
- 你的项目中 MQ 的作用?
- 为什么选择这款 MQ 作为消息中间件?
- 重复消费怎么办?
- 如何确保消息被消费?
- 有遇到其他问题吗? 那么接下来带着问题先思考下,有好的想法可以在评论区留言,大家一起分享。
消息中间件在系统中的使用
我之前写过一篇关于 rocketMQ 实现分布式锁的文章,主要介绍如何使用 RocketMQ 实现分布式锁,
《Springcloud + RocketMQ 解决分布式事务》
但是这个功能并不是 MQ 基本功能,也不是所有 MQ 都有的功能。
MQ 在系统中到底有哪些作用呢?抛开基本的消息发布订阅不说,还有以下几点:
- 分布式系统解耦
- 不需要立即返回的业务异步处理
- 削峰填谷,不直接访问服务,缓解服务压力,增加性能
- 日志记录
分布式系统解耦
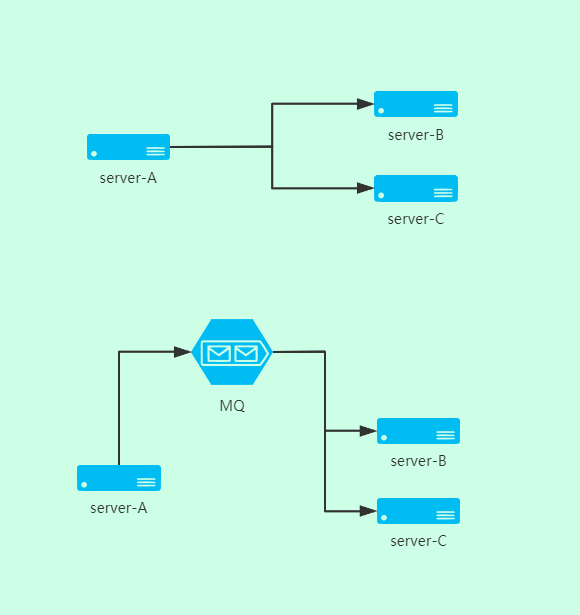
在分布式系统中,要么是通过 rest 调用,要么是通过 dubbo 等 RPC 调用,但是有些场景需要解耦设计,不能直接调用。
比如消息驱动的系统中,消息发送者完成本地业务,发送消息,多平台的消息消费者服务需要收到推送的消息,然后继续处理其他业务。
看这两个架构图,第一种 BC 都直接依赖 A 服务,那么如果 A 中的接口修改,BC 都要跟着做修改,耦合度高。
第二种,通过 MQ 来作为中间件收发消息,BC 只依赖收到的消息而不是具体的接口,这样即使 A 服务修改或者增加其他服务,都只要订阅MQ就行。
不要求实时的业务异步处理
用户注册业务流程为例,
- 用户注册入库
- 用户验证邮件发送
- 用户验证短信发送
原来的系统设计,这样的服务流程会串行处理,即先 1-2-3 ;但是这里可以思考下,如果单个服务单台机器的情况下,注册用户特别多,系统能不能抗住?
这里假设各个阶段的时间 1 = 50ms , 2 = 50ms , 3 = 50ms,那么一个请求下来就是 all = 150ms;
这里再假设,这个服务器 CPU = 1 , 且只能处理单线程,那么以这种单台服务器单线程的 QPS 来算;QPS = 1000/150 ≈ 7
现在我要让这个 QPS * 3 提升三倍,这个时候引入 MQ 服务作为中间件
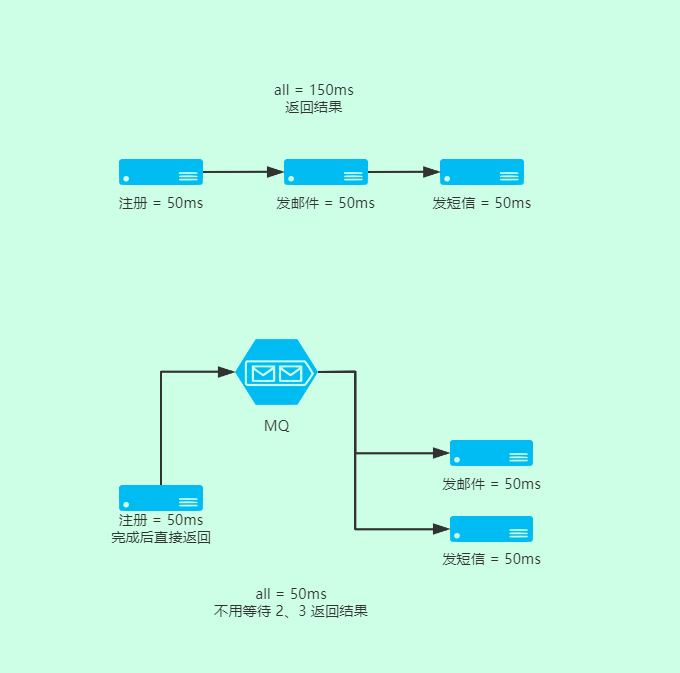
如图可见,我在 A 服务用户注册完成后,就直接返回了,这个时候 MQ 用来发送异步处理消息,B,C 服务分别处理。 A 不用等待 B、C 的返回结果 ,这样用户体验就是只有 50ms 等待时间。而在邮件、短信这个阶段,因为网络延迟原因, 用户可以接受一定时间的等待。
削峰填谷
一般的服务,我们的请求访问到系统都是直接请求,这样的模式在用户访问量不大的情况下,问题不是很大。
但是如果用户请求达到了一定的瓶颈或者产生了一些问题,我们就需要考虑优化我们的架构设计,MQ 中间件正是解决办法之一。
下面以秒杀系统为例分析问题
秒杀系统瞬间百万并发,怎么处理?一般秒杀系统会进行请求过滤,无效、重复都会被过滤一遍,剩下的才真正进入到秒杀服务、订单服务。
但即使这样并发仍然很高,如果网关把全部请求都转发到下游订单服务,一样会压垮下游系统,造成服务不可用甚至雪崩。
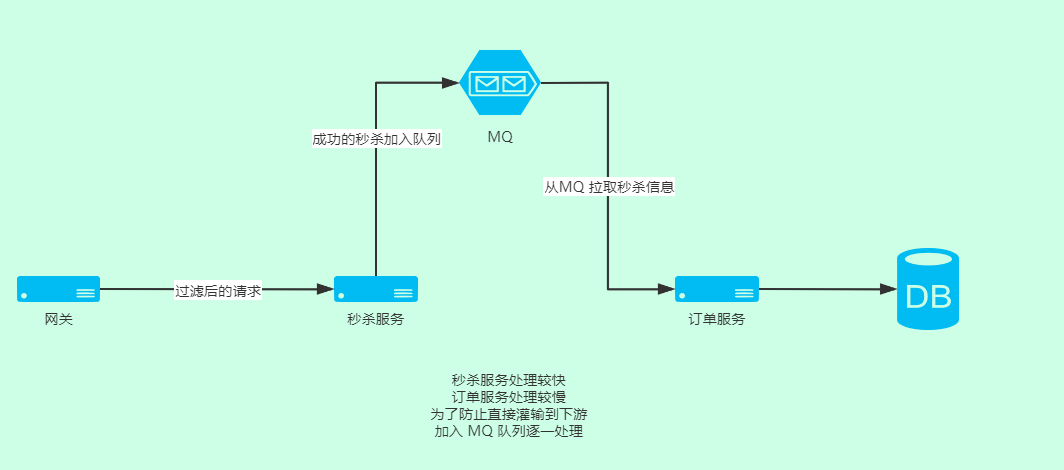 真实的秒杀系统更复杂 ,包含 Nginx 、网关、注册中心、redis 缓存、mysql 集群、消息队列集群
真实的秒杀系统更复杂 ,包含 Nginx 、网关、注册中心、redis 缓存、mysql 集群、消息队列集群
解决方式就是将上游处理的较快的任务,加入到队列处理,下游逐一消费队列,直到所有队列消费完成。
假如秒杀服务处理请求数:1000/s,
下游订单服务处理请求书:10/s,
为了不给下游订单服务造成压力,秒杀后的信息发送到队列,订单服务就可以从容淡定的每秒处理十个,而不是直接塞 1000 个请求
也不管人家愿意不愿意。
到这里,可以总结下秒杀系统的过滤方式:
- 页面按钮点击一次置灰
- 每秒透过请求数限制,例如 100/s,可以使用 Nginx ,sentinel
- 过滤同一用户的重复请求,通过用户唯一标识、商品信息,
- 通过消息队列存储成功的秒杀信息,下游订单系统处理
日志
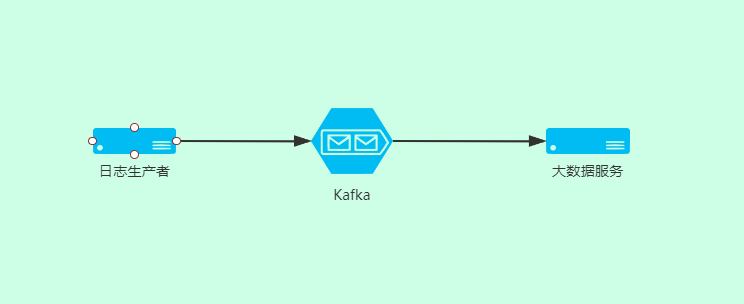
所有服务都将日志发送到 MQ 服务用来作为日志存储。
MQ 作为中间件对日志进行持久化、转发
大数据服务对 MQ 读取和进行日志分析
MQ 怎么选
有人上来就是一通性能比较,然后说 RabbitMQ 是世界上最好的 MQ…
你把挑选 MQ 比作挑老婆吧,上来就要全套,肤白貌美、前凸后翘、性感火辣、勤劳能干。。。
真是缺乏社会的教育啊,兄弟
养得起吗?动不动一套保养套餐,1W/月
守得住吗?隔壁老王经常来你家吃饭吧,疯狂脑补。。。
吃的消吗?红枣+枸杞+肾宝片,怕是心有余力不足吧
言归正传,其实我觉得这是一个思考题,首先我们要看的应该是条件是哪些?
- 用途?是用来做日志、解耦、还是异步处理
- 公司情况?人员是否充足,现有人员技术栈情况,人员的技术栈实力
- 项目情况?项目周期,人员,用户量,架构设计,是否老项目
- 主流 MQ 现状?稳定可靠度,社区活跃度,文档全面性,云服务支持情况
上图的例子日志消息就是使用的 kafka,为什么是kafka?
Kafka是LinkedIn开源的分布式发布-订阅消息系统,属于 Apache 顶级项目,社区活跃。
Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输。
后来版本开始支持复制,不支持事务,对消息的重复、丢失、错误没有严格要求,适合产生大量数据的互联网服务的数据收集业务。
但是 kafka 相对来说很重,需要依赖 zookeeper,大公司里使用没问题,也少不了专人维护。
RocketMQ 是阿里开源的一套可靠消息系统,已经捐赠 Apache 成为顶级项目。刚开始定位于非日志的可靠消息传输,其实在日志处理方面性能也不错。 目前支持的客户端包括 java,c++,GO ,社区比较活跃,文档还算全面。但是涉及到核心的要修改还是有难度的,毕竟阿里云靠卖这个服务赚钱呢。 所以如果公司实力不自信还是慎重选择吧,实在不行可以直接购买云服务,省心省力,还是那句话,看实际情况。
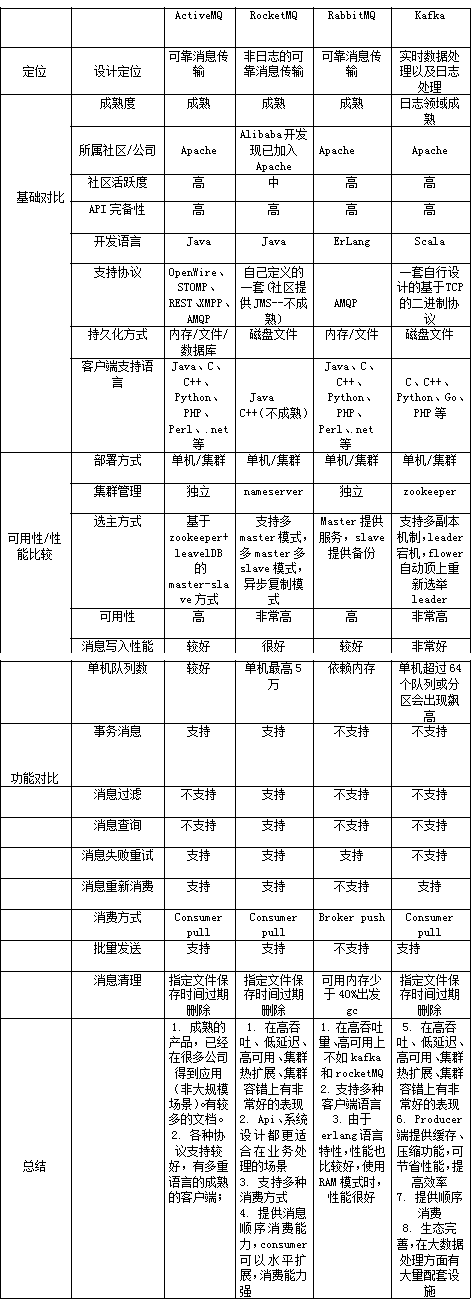
主流 MQ 的特点
下图是来源网络的图片,部分描述已经过时,但是基本不差,仅供参考:
如何确保消息不被重复消费
这里简单说说,后面专门针对这个问题进行书写招供。
大致就是一些特殊原因例如网络原因,服务重启造成消息消费未被记录,造成重复消费的可能。
一般的处理方式就是保证接口设计的幂等性,主旨通过唯一标识判断是否存在。
- redis 缓存使用,唯一性 token 保存redis,每次消费后删除 token
- 唯一主键判断,数据库判断是否存在该主键记录,存在则更新,不存在则插入
喜欢文章请关注我
程序领域
点击关注+转发,私信发送【面试】或者【资料】可以收获更多资源
